
近日,鹏城实验室联合清华大学研制成功首个国产算力下全开源模型“鹏城·脑海-2.1-开元-2B”(以下简称“脑海2.1-开元2B”),该模型在“中国算力网”核心节点“鹏城云脑Ⅱ”(国产芯片生态)上进行训练数据清洗、去重和训练的全流程,并完全公开过程和代码,不仅为中国算力网和业界提供了一条可复现、可迭代的模型全流程透明技术路径,也解码了在国产算力平台上实现高效、稳定预训练的完整解决方案。
“脑海2.1-开元2B”作为“鹏城·脑海”系列大模型的重要成员,是继推出大规模200B模型和对标GPT-4 Turbo的33B中等尺寸长窗口模型之后,进一步在全球大模型领域开放平台Hugging Face上全开源的2B新版模型(https://hf-mirror.com/thu-pacman/PCMind-2.1-Kaiyuan-2B)。与现有大量模型仅开源权重不同,该模型公开了训练数据、清洗和配比工具以及模型权重和技术报告等核心“秘诀”,助力开源生态发展,训练中涉及的所有原始数据集均具有宽松的开源协议(如CC、Apache、MIT、ODC等),个人、院校、企业、科研机构等均可自由使用。该模型跨越了“从粗放到集约”、“从开源权重到开源过程”的国产模型里程碑,依托“鹏城云脑”大科学装置为代表的全国产算力与全生命周期工具链,为自主创新AI生态铺路,切实普惠普及开发者和用户。
针对当前高质量开源数据稀缺、国产算力芯片(FP16精度)训练不稳定以及开源模型训练方案“黑盒化”等难题,“脑海2.1-开元2B”的研发实现了全国产算力上精炼数据高效训练的自主可控技术路线,具体包括以下要点。
一是数据混合与处理框架,解决了海量异构数据质量评价标准不统一及处理效率低的问题。
· Kaiyuan-Spark处理框架:研发了基于Spark的分布式处理系统,采用树状流水线设计和全流程YAML配置管理,确保了数据处理的可复现性。通过集成诸葛弩(Chukonu)计算框架进行底层加速,在MinHash全局模糊去重任务中实现了端到端2.5倍的加速比,高效完成了15T级原始数据的精炼。
· 分位标定法(Quantile Benchmarking):创新提出通过小规模探针实验(0.5B模型+10B数据),构建数据质量分数与下游任务表现的映射关系,解决了不同开源数据集(如FineWeb-Edu与DCLM)质量标签不可比的难题,为科学的数据配比提供了量化依据。

(分位标定流程示意图)
二是训练策略与超参配置,克服了有限算力资源下高质量数据利用率不足的挑战。
· 策略性数据重复(Strategic Manual Repetition):在多阶段训练中,针对识别出的Top 10%高质量数据进行适度重复训练(最多4轮),实验证明其效果显著优于传统的单轮训练,有效缓解了高质量数据的稀缺性。
· 多领域混合课程学习(Curriculum Decay Model Average):在训练后期通过领域内质量排序和领域间比例均衡,引导模型从易到难渐进学习,并配合多Checkpoint权重平均技术,在降低训练噪声的同时提升了收敛稳定性。
· 动态配比五阶段训练:将训练分为五个阶段,随进程逐步提升数学、代码及中文数据的比例,英语内容保持在30%以上以维持通用能力,最终在2.2T tokens上完成了高效预训练。
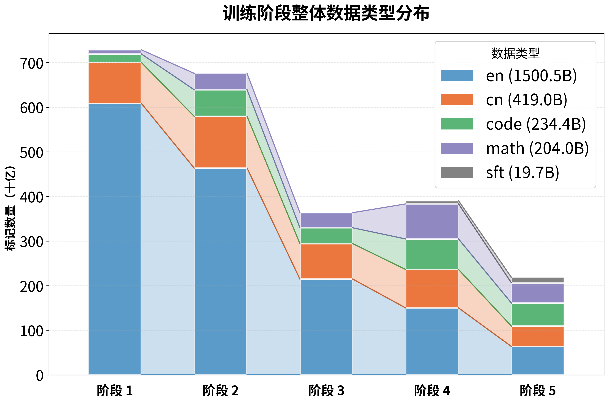
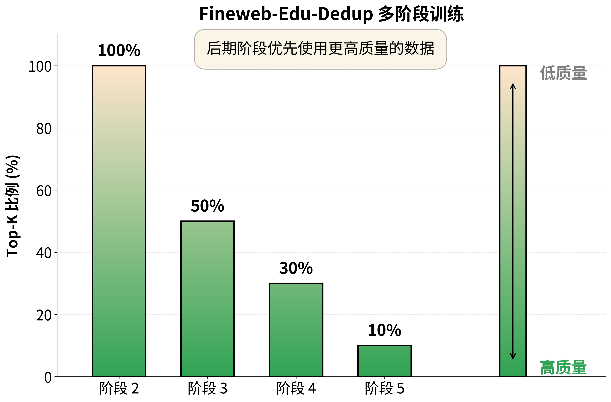

(多阶段数据比例调整趋势图以及多领域混合课程学习训练策略对比图)
三是稳定训练与模型架构,突破了某国产算力芯片(FP16精度)环境下梯度溢出和数值不稳定的瓶颈。
· 三明治范数(Sandwich Norm)与QK Norm:针对FP16精度表示范围小的限制,在Transformer每层前后引入归一化层,并使用QK Norm替换传统的Soft-Capping,将激活值的L1范数控制在安全区间,防止数值在累积中溢出。
· 软裁剪(Soft Clipping):对输出logits应用tanh非线性变换,有效缓解了由于离群值导致的梯度爆炸问题,确保了1024张国产算力芯片集群长达12.5天高强度训练的稳定性。
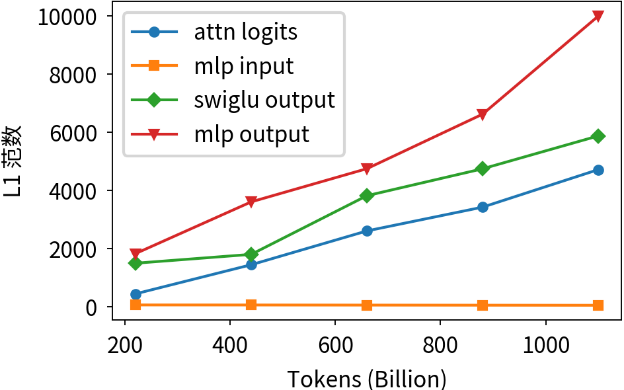

(FP16训练稳定性对比曲线)
目前,“脑海2.1-开元2B”评测结果已达到同规模全开源模型领先、部分指标接近主流闭源方案的水平。在核心能力(数学、代码、中文)评测中,该模型在MATH(30.34)、HumanEval(42.68)及CMMLU(49.25)等指标上显著超越了SmolLM2-1.7B及Gemma2-2B等国际主流全开源模型。在通用推理与知识方面,其平均分达到67.74,以更少的参数量(1.4B non-embedding)实现了与更大规模模型(如YuLan-Mini-2.4B)相当的性能。


(“脑海2.1-开元2B”与国内外同规模模型基准测试得分表)

(“脑海2.1-开元2B”达到同规模全开源模型领先、部分指标接近主流闭源方案的水平)
下一步,鹏城实验室将依托“鹏城云脑Ⅱ”和建设中的新一代国产智能算力“鹏城云脑Ⅲ”,持续开展基于全开源数据和国产算力训练高水平全开源大模型,并依托“中国算力网”,部署包括全开源模型在内的国产开源模型,为千行百业提供开源开放的模型与算力支撑。
相关链接
• 模型: https://hf-mirror.com/thu-pacman/PCMind-2.1-Kaiyuan-2B
• 数据集:https://hf-mirror.com/datasets/thu-pacman/PCMind-2.1-Kaiyuan-2B
• 技术报告:https://www.arxiv.org/abs/2512.07612
• 数据处理框架:https://github.com/thu-pacman/Kaiyuan-Spark
• 训练框架:https://github.com/thu-pacman/kaiyuan-mindformers


